Transformers: The rise and rise of Hugging Face
Transformers: The rise and rise of Hugging Face
Transformers: The rise and rise of Hugging Face
With 60,000+ stars on GitHub, 40,000+ models, and millions of monthly visits, Hugging Face is one of the fastest-growing projects in open source software history
With 60,000+ stars on GitHub, 40,000+ models, and millions of monthly visits, Hugging Face is one of the fastest-growing projects in open source software history
With 60,000+ stars on GitHub, 40,000+ models, and millions of monthly visits, Hugging Face is one of the fastest-growing projects in open source software history

“The original agreement on the European Economic Area was signed in August 1992.”
Let’s try translating that sentence to French.
Taking a first pass at the phrase “the European Economic Area”, you might be tempted to go word by word, arrive at “la européen économique zone” and be met with a confused stare from the Parisian you decided to bother on the TGV.
As any Frenchman/Frenchwoman will tell you, “Economic” precedes “European” in French, and gendered agreement rules dictate that “European” be translated to “européenne” in the feminine form to match “économique.” Given the context of gender agreements and flipped orders, the correct translation is “la zone économique européenne.”
This is an example that researchers at Google Brain used to illustrate the magic of the “transformer” model in a 2017 paper titled “Attention is all you need” - the greatest thing to happen to Natural Language Processing/Understanding (NLP/U) since sliced bread.
Here’s what was unique about transformer models - “Positional encoding” enabled transformers to be trained much, much faster on larger datasets - or slices of the internet. Self-attention enabled these models to understand a word in the context of other words around it. For example, a transformer can learn to interpret “bark” differently when used alongside “tree”, versus “dog.”

Understanding the underlying meaning and context of an input is a pretty powerful thing, and is the secret sauce powering all the cutting-edge NLP-powered tools you’re likely to encounter today: Grammarly’s grammatical error detection, GitHub copilot, GMail’s ‘autocomplete’, CopyAI’s AI copywriter, and even DALL-E 2.
Today, if you want to leverage the power of transformers, and don’t have the processing power of Google to build it from scratch (we’ll pause while you check) you can, thanks to three européens who open-sourced the transformers library (and many others too, btw) and are well on their way to democratizing machine-learning - Clem Delangue, Julien Chaumond, and Thomas Wolf - co-founders of 🤗 - Hugging Face.
Dirt bikes to Chatbots to the GitHub for ML ⏭
If you ever took an ATV out for a spin in France, there’s a non-zero probability that it was once in the Hugging Face founder Clem Delangue’s garden equipment shop. Clem’s first steps into the world of entrepreneurship were through selling ATVs and dirt bikes imported from China on eBay - who were so impressed that they asked him to come intern with them. Clem met machine learning and machine learning met Clem when the co-founder of Moodstocks, a start-up working on image recognition tech, accosted him at an e-commerce trade show. After a short stint here, Clem started up on his own, with no ATVs this time. Bit by the ML bug, his work on a collaborative note-taking app idea connected him with a fellow entrepreneur building a collaborative e-book reader - Julien Chaumond.

The duo met with Chaumond’s friend from college, who was now active in ML research, and together they set out to build an “open-domain Conversational AI” - the sort of AI that features in the movie “Her.”
“We’re building an AI so that you’re having fun talking with it. When you’re chatting with it, you’re going to laugh and smile — it’s going to be entertaining.” - Clem Delangue, CEO & Co-founder
The original app was a Tamagotchi-like friend chatbot that could talk back to you coherently about a wide range of topics, but also detect emotions in text, and adapt its tone accordingly.
The big pivot ⏎
Julien says that the chatbot was an excuse for the early team to dive into the state-of-the-art NLP and the bleeding-edge research of the time. It was an early runaway success, with ~100,000 DAU (daily active users) at its peak and decent retention numbers. For the early team of 5-6 NLP-heads however, the heart was where the tech was. And frustratingly, the massive leaps they made to their underlying tech did not translate to breakthroughs in consumer usage. Accuracy improvements in the Hugging Face bot’s responses didn’t seem to correlate with growth or retention.
Around two years later, the “Attention is all you need” paper marked the beginning of the age of transformers. Hugging Face, who had already released parts of the powerful library powering their chatbot as an open-source project on GitHub, open-sourced the hot new thing in NLP and made it available to the community.
On May 7, they raised $100 million in Series C funding at a $2B valuation led by Lux Capital with major participation from Sequoia, and Coatue. The hotly contested round also saw support from existing investors Addition, NBA star Kevin Durant, a_capital, SV Angel, Betaworks, AIX Ventures, Rich Kleiman from Thirty Five Ventures, Olivier Pomel (co-founder & CEO at Datadog), and others.
Racing to the cutting-edge 🏎
Since pivoting away from the chatbot, Hugging Face has been on a mission to advance and democratize artificial intelligence through open source and open science.
To become the GitHub for machine learning.
With ~100,000 pre-trained machine-learning models and <10,000 datasets currently hosted on the platform, Hugging Face enables the community and 10,000+ companies including Grammarly, Chegg, and others to build their own NLP capabilities, share their own models, and more.
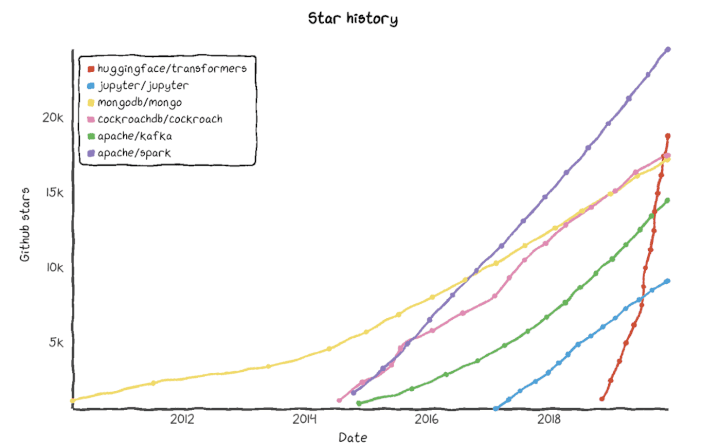
Hugging Face’s rise to the cutting-edge is mirrored in the star history of Transformers on Github compared to other leading open-source projects - even Confluent, MongoDB, and Databricks.
How did the NYC/Paris-based company named after an emoticon with just under 10 employees until 2019 rise to the very top, and become one of the most prestigious companies for a data scientist to work for today? Let’s try and break down the sorcery.
Community-led growth 👥
Even in the early days of Hugging Face, the founders were quick to notice that the community of people interested in “large language models applied to text” was dense. In open-sourcing their early libraries, they stumbled upon a handful of super-users in the community. After Google released model weights for the language representation model BERT in TensorFlow, the very first starting point of Hugging Face’s repo was moving this model to Pytorch - it was here that they really discovered their core group of contributors.
Hugging Face aspires to build the #1 community for machine learning. The commitment to the community is seared into the cultural fabric of the company:
“Everyone in the team should have some kind of focus on usage on community. If we want to build the best community for ML, we want to make sure everyone on the team is passionate about working with the community.” - Julien Chaumond
Hugging Face taps into some key community dynamics that drive engagement and growth. Chief among them was the Hugging Face Hub. The team started building the hub when they found the need for a platform for users of transformers and dataset libraries to easily share their models or datasets. They hacked together a simple way for the community to publish to AWS S3, etc if they wanted to. The Hub hosts Git-based repositories which are storage spaces that can contain all user files. It currently hosts three repo types:
Spaces - The recently launched Hugging Face Spaces empowers members of the community to become creators and contributors. Spaces are a simple way to build and share apps with in-built control versioning and git-based workflows. Over 200 spaces are live on the website today.
Datasets - Hugging Face is home to ~4.8k datasets with a broad range of use cases, tasks, and languages.
Models - Hugging Face is home to ~45k models with applications ranging from image classification and segmentation, audio classification, automatic speech recognition, zero-shot classification, and more.
Here’s the RoBERTa base model making a strong case for simplicity in life:
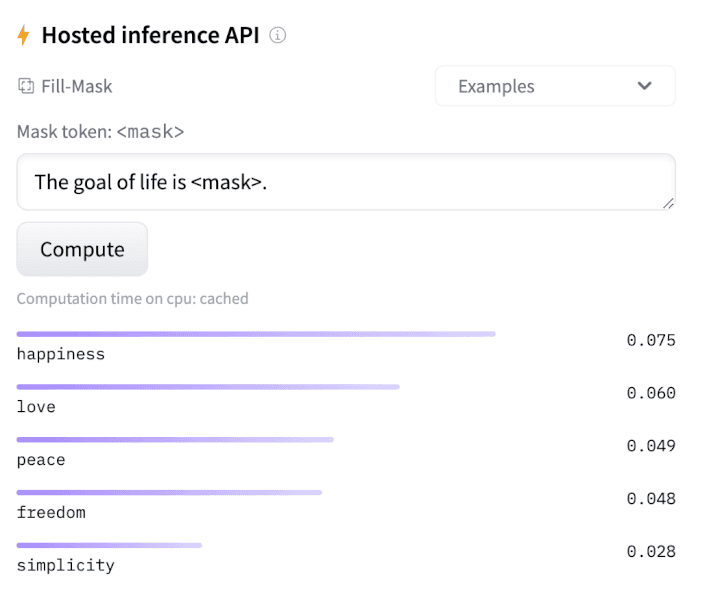
Hugging Face also hosts an Inference API that lets users access models via a programming interface, and “AutoTrain” them.
Open-source to open doors 🗃
CEO and co-founder Clem believes that with open-source models, Hugging Face can harness the power of a community to do things differently - “deliver a 1000 times more value” than a proprietary tool, he says, drawing parallels to Elastic and MongoDB. Clem says that in the field of NLP, the team has always felt like they had been standing on the shoulders of giants and that no one company - not even the legacy tech giants can push the envelope by themselves.
What started with open-sourcing PyTorch BERT and GPT led to a snowballing effect that has propelled Hugging Face to where they are today. In a field like NLP or Machine Learning, Clem believes that the worst position to be in is to be in competition with research labs and open source projects. He says that even monetizing 1% of the value created while tapping into the power of the community can often be more than enough to grow even a publicly-traded company.
Usage is deferred revenue 💸
“Given how valuable machine learning is and how mainstream it’s becoming, usage is deferred revenue,” Clem Delangue
For Hugging Face, monetization is still an early play - they started their paid offerings just last year, and already count 1000+ companies as customers including Intel, eBay, Pfizer, and Roche. The advances in transfer learning meant that transformers are effective not just in NLP, but in other domains as well. The opportunity to become the GitHub for machine learning was apparent and Hugging Face decided to pounce on that opportunity. With ~$10M in revenue in the bank along with most of their $40M Series B from March 2021, and a strong community driving them forward, the product-led growth flywheel is ready to kick into high gear.
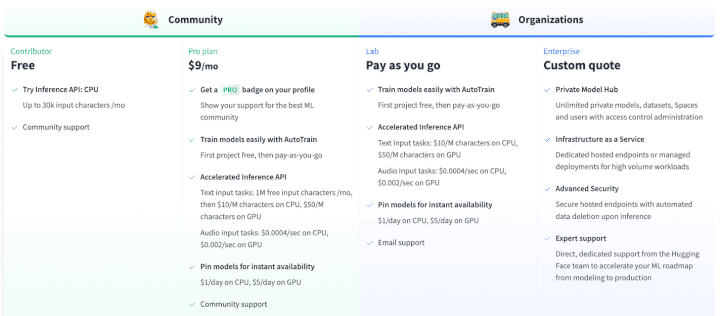
On the GTM front, with the hot $100M Series C in the bag, Hugging Face is hiring AEs, BDRs, and Enterprise Sales to layer into their organic growth flywheel.
“I don’t really see a world where machine learning becomes the default way to build technology and where Hugging Face is the No. 1 platform for this, and we don’t manage to generate several billion dollars in revenue.” - Clem
What’s next for Hugging Face? [MASK] 🔮
With a team of ~140 that’s rapidly growing every month, and offices in New York and Paris, team Hugging Face is edging closer and closer to their goal of democratizing machine learning, and making bleeding-edge AI accessible to even companies and teams without the resources to build them from scratch.
Transformers evolving to become a general-purpose architecture for speech, computer vision, and even protein structure prediction holds Hugging Face in good stead - at the intersection of overlapping domains.
With what Andrej Karpathy calls Software 2.0 around the corner if not already here, and open-domain conversational AI still an open-problem statement, there are exciting milestones to hit before 🤗 becomes the first company to go public on Nasdaq with an emoji, instead of the three-letter ticker.
“The original agreement on the European Economic Area was signed in August 1992.”
Let’s try translating that sentence to French.
Taking a first pass at the phrase “the European Economic Area”, you might be tempted to go word by word, arrive at “la européen économique zone” and be met with a confused stare from the Parisian you decided to bother on the TGV.
As any Frenchman/Frenchwoman will tell you, “Economic” precedes “European” in French, and gendered agreement rules dictate that “European” be translated to “européenne” in the feminine form to match “économique.” Given the context of gender agreements and flipped orders, the correct translation is “la zone économique européenne.”
This is an example that researchers at Google Brain used to illustrate the magic of the “transformer” model in a 2017 paper titled “Attention is all you need” - the greatest thing to happen to Natural Language Processing/Understanding (NLP/U) since sliced bread.
Here’s what was unique about transformer models - “Positional encoding” enabled transformers to be trained much, much faster on larger datasets - or slices of the internet. Self-attention enabled these models to understand a word in the context of other words around it. For example, a transformer can learn to interpret “bark” differently when used alongside “tree”, versus “dog.”
Understanding the underlying meaning and context of an input is a pretty powerful thing, and is the secret sauce powering all the cutting-edge NLP-powered tools you’re likely to encounter today: Grammarly’s grammatical error detection, GitHub copilot, GMail’s ‘autocomplete’, CopyAI’s AI copywriter, and even DALL-E 2.
Today, if you want to leverage the power of transformers, and don’t have the processing power of Google to build it from scratch (we’ll pause while you check) you can, thanks to three européens who open-sourced the transformers library (and many others too, btw) and are well on their way to democratizing machine-learning - Clem Delangue, Julien Chaumond, and Thomas Wolf - co-founders of 🤗 - Hugging Face.
Dirt bikes to Chatbots to the GitHub for ML ⏭
If you ever took an ATV out for a spin in France, there’s a non-zero probability that it was once in the Hugging Face founder Clem Delangue’s garden equipment shop. Clem’s first steps into the world of entrepreneurship were through selling ATVs and dirt bikes imported from China on eBay - who were so impressed that they asked him to come intern with them. Clem met machine learning and machine learning met Clem when the co-founder of Moodstocks, a start-up working on image recognition tech, accosted him at an e-commerce trade show. After a short stint here, Clem started up on his own, with no ATVs this time. Bit by the ML bug, his work on a collaborative note-taking app idea connected him with a fellow entrepreneur building a collaborative e-book reader - Julien Chaumond.
The duo met with Chaumond’s friend from college, who was now active in ML research, and together they set out to build an “open-domain Conversational AI” - the sort of AI that features in the movie “Her.”
“We’re building an AI so that you’re having fun talking with it. When you’re chatting with it, you’re going to laugh and smile — it’s going to be entertaining.” - Clem Delangue, CEO & Co-founder
The original app was a Tamagotchi-like friend chatbot that could talk back to you coherently about a wide range of topics, but also detect emotions in text, and adapt its tone accordingly.
The big pivot ⏎
Julien says that the chatbot was an excuse for the early team to dive into the state-of-the-art NLP and the bleeding-edge research of the time. It was an early runaway success, with ~100,000 DAU (daily active users) at its peak and decent retention numbers. For the early team of 5-6 NLP-heads however, the heart was where the tech was. And frustratingly, the massive leaps they made to their underlying tech did not translate to breakthroughs in consumer usage. Accuracy improvements in the Hugging Face bot’s responses didn’t seem to correlate with growth or retention.
Around two years later, the “Attention is all you need” paper marked the beginning of the age of transformers. Hugging Face, who had already released parts of the powerful library powering their chatbot as an open-source project on GitHub, open-sourced the hot new thing in NLP and made it available to the community.
On May 7, they raised $100 million in Series C funding at a $2B valuation led by Lux Capital with major participation from Sequoia, and Coatue. The hotly contested round also saw support from existing investors Addition, NBA star Kevin Durant, a_capital, SV Angel, Betaworks, AIX Ventures, Rich Kleiman from Thirty Five Ventures, Olivier Pomel (co-founder & CEO at Datadog), and others.
Racing to the cutting-edge 🏎
Since pivoting away from the chatbot, Hugging Face has been on a mission to advance and democratize artificial intelligence through open source and open science.
To become the GitHub for machine learning.
With ~100,000 pre-trained machine-learning models and <10,000 datasets currently hosted on the platform, Hugging Face enables the community and 10,000+ companies including Grammarly, Chegg, and others to build their own NLP capabilities, share their own models, and more.
Hugging Face’s rise to the cutting-edge is mirrored in the star history of Transformers on Github compared to other leading open-source projects - even Confluent, MongoDB, and Databricks.
How did the NYC/Paris-based company named after an emoticon with just under 10 employees until 2019 rise to the very top, and become one of the most prestigious companies for a data scientist to work for today? Let’s try and break down the sorcery.
Community-led growth 👥
Even in the early days of Hugging Face, the founders were quick to notice that the community of people interested in “large language models applied to text” was dense. In open-sourcing their early libraries, they stumbled upon a handful of super-users in the community. After Google released model weights for the language representation model BERT in TensorFlow, the very first starting point of Hugging Face’s repo was moving this model to Pytorch - it was here that they really discovered their core group of contributors.
Hugging Face aspires to build the #1 community for machine learning. The commitment to the community is seared into the cultural fabric of the company:
“Everyone in the team should have some kind of focus on usage on community. If we want to build the best community for ML, we want to make sure everyone on the team is passionate about working with the community.” - Julien Chaumond
Hugging Face taps into some key community dynamics that drive engagement and growth. Chief among them was the Hugging Face Hub. The team started building the hub when they found the need for a platform for users of transformers and dataset libraries to easily share their models or datasets. They hacked together a simple way for the community to publish to AWS S3, etc if they wanted to. The Hub hosts Git-based repositories which are storage spaces that can contain all user files. It currently hosts three repo types:
Spaces - The recently launched Hugging Face Spaces empowers members of the community to become creators and contributors. Spaces are a simple way to build and share apps with in-built control versioning and git-based workflows. Over 200 spaces are live on the website today.
Datasets - Hugging Face is home to ~4.8k datasets with a broad range of use cases, tasks, and languages.
Models - Hugging Face is home to ~45k models with applications ranging from image classification and segmentation, audio classification, automatic speech recognition, zero-shot classification, and more.
Here’s the RoBERTa base model making a strong case for simplicity in life:
Hugging Face also hosts an Inference API that lets users access models via a programming interface, and “AutoTrain” them.
Open-source to open doors 🗃
CEO and co-founder Clem believes that with open-source models, Hugging Face can harness the power of a community to do things differently - “deliver a 1000 times more value” than a proprietary tool, he says, drawing parallels to Elastic and MongoDB. Clem says that in the field of NLP, the team has always felt like they had been standing on the shoulders of giants and that no one company - not even the legacy tech giants can push the envelope by themselves.
What started with open-sourcing PyTorch BERT and GPT led to a snowballing effect that has propelled Hugging Face to where they are today. In a field like NLP or Machine Learning, Clem believes that the worst position to be in is to be in competition with research labs and open source projects. He says that even monetizing 1% of the value created while tapping into the power of the community can often be more than enough to grow even a publicly-traded company.
Usage is deferred revenue 💸
“Given how valuable machine learning is and how mainstream it’s becoming, usage is deferred revenue,” Clem Delangue
For Hugging Face, monetization is still an early play - they started their paid offerings just last year, and already count 1000+ companies as customers including Intel, eBay, Pfizer, and Roche. The advances in transfer learning meant that transformers are effective not just in NLP, but in other domains as well. The opportunity to become the GitHub for machine learning was apparent and Hugging Face decided to pounce on that opportunity. With ~$10M in revenue in the bank along with most of their $40M Series B from March 2021, and a strong community driving them forward, the product-led growth flywheel is ready to kick into high gear.
On the GTM front, with the hot $100M Series C in the bag, Hugging Face is hiring AEs, BDRs, and Enterprise Sales to layer into their organic growth flywheel.
“I don’t really see a world where machine learning becomes the default way to build technology and where Hugging Face is the No. 1 platform for this, and we don’t manage to generate several billion dollars in revenue.” - Clem
What’s next for Hugging Face? [MASK] 🔮
With a team of ~140 that’s rapidly growing every month, and offices in New York and Paris, team Hugging Face is edging closer and closer to their goal of democratizing machine learning, and making bleeding-edge AI accessible to even companies and teams without the resources to build them from scratch.
Transformers evolving to become a general-purpose architecture for speech, computer vision, and even protein structure prediction holds Hugging Face in good stead - at the intersection of overlapping domains.
With what Andrej Karpathy calls Software 2.0 around the corner if not already here, and open-domain conversational AI still an open-problem statement, there are exciting milestones to hit before 🤗 becomes the first company to go public on Nasdaq with an emoji, instead of the three-letter ticker.
Related Articles

Behavioral Retargeting: A Game-Changer in the Cookieless Era
Unlock the power of behavioral retargeting for the cookieless future! Learn how it personalizes ads & boosts conversions. #behavioralretargeting

All of Toplyne's 40+ Badges in the G2 Spring Reports
Our customers awarded us 40+ badges in G2's Summer Report 2024.

Unlocking the Full Potential of Google PMax Campaigns: Mastering Audience Selection to Double Your ROAS
Copyright © Toplyne Labs PTE Ltd. 2024
Copyright © Toplyne Labs PTE Ltd. 2024
Copyright © Toplyne Labs PTE Ltd. 2024
Copyright © Toplyne Labs PTE Ltd. 2024